
大数据的数据来源广泛,应用需求和数据类型都不尽相同,但是最基本的处理流程是一致的。
整个大数据的处理流程可以定义为,在合适工具的辅助下,对广泛异构的数据源进行抽取和集成,将结果按照一定的标准进行统一存储,然后利用合适的数据分析技术对存储的数据进行分析,从中提取有益的知识,并利用恰当的方式将结果展现给终端用户。
具体来讲,大数据处理的基本流程可以分为数据抽取与集成、数据分析和数据解释等步骤。
数据抽取与集成
大数据的一个重要特点就是多样性,这就意味着数据来源极其广泛,数据类型极为繁杂。这种复杂的数据环境给大数据的处理带来极大的挑战。
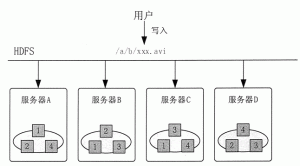
要想处理大数据,首先必须对所需数据源的数据进行抽取和集成,从中提取出数据的实体和关系,经过关联和聚合之后采用统一定义的结构来存储这些数据。
在数据集成和提取时,需要对数据进行清洗,保证数据质量及可信性。同时还要特别注意大数据时代数据模式和数据的关系,大数据时代的数据往往是先有数据再有模式,并且模式是在不断的动态演化之中的。
数据抽取和集成技术并不是一项全新的技术,在传统数据库领域此问题就已经得到了比较成熟的研究。随着新的数据源的涌现,数据集成方法也在不断的发展之中。
从数据集成模型来看,现有的数据抽取与集成方式可以大致分为 4 种类型:基于物化或 ETL 方法的引擎、基于联邦数据库或中间件方法的引擎、基于数据流方法的引擎,以及基于搜索引擎的方法。
数据分析
数据分析是整个大数据处理流程的核心,大数据的价值产生于分析过程。
从异构数据源抽取和集成的数据构成了数据分析的原始数据。根据不同应用的需求可以从这些数据中选择全部或部分进行分析。
小数据时代的分析技术,如统计分析、数据挖掘和机器学习等,并不能适应大数据时代数据分析的需求,必须做出调整。大数据时代的数据分析技术面临着一些新的挑战,主要有以下几点。
1)数据量大并不一定意味着数据价值的增加,相反这往往意味着数据噪音的增多。
因此,在数据分析之前必须进行数据清洗等预处理工作,但是预处理如此大量的数据,对于计算资源和处理算法来讲都是非常严峻的考验。
2)大数据时代的算法需要进行调整。
首先,大数据的应用常常具有实时性的特点,算法的准确率不再是大数据应用的最主要指标。
在很多场景中,算法需要在处理的实时性和准确率之间取得一个平衡。其次,分布式并发计算系统是进行大数据处理的有力工具,这就要求很多算法必须做出调整以适应分布式并发的计算框架,算法需要变得具有可扩展性。
许多传统的数据挖掘算法都是线性执行的,面对海量的数据很难在合理的时间内获取所需的结果。因此需要重新把这些算法实现成可以并发执行的算法,以便完成对大数据的处理。
最后,在选择算法处理大数据时必须谨慎,当数据量增长到一定规模以后,可以从小量数据中挖掘出有效信息的算法并一定适用于大数据。
3)数据结果的衡量标准。
对大数据进行分析比较困难,但是对大数据分析结果好坏的衡量却是大数据时代数据分析面临的更大挑战。
大数据时代的数据量大,类型混杂,产生速度快,进行分析的时候往往对整个数据的分布特点掌握得不太清楚,从而会导致在设计衡量的方法和指标的时候遇到许多困难。
数据解释
数据分析是大数据处理的核心,但是用户往往更关心对结果的解释。如果分析的结果正确,但是没有采用适当的方法进行解释,则所得到的结果很可能让用户难以理解,极端情况下甚至会引起用户的误解。
数据解释的方法很多,比较传统的解释方式就是以文本形式输出结果或者直接在电脑终端上显示结果。这些方法在面对小数据量时是一种可行的选择。
但是大数据时代的数据分析结果往往也是海量的,同时结果之间的关联关系极其复杂,采用传统的简单解释方法几乎是不可行的。
解释大数据分析结果时,可以考虑从以下两个方面提升数据解释能力。
1)引入可视化技术。
可视化作为解释大量数据最有效的手段之一率先被科学与工程计算领域采用。
该方法通过将分析结果以可视化的方式向用户展示,可以使用户更易理解和接受。常见的可视化技术有标签云、历史流、空间信息流等。
2)让用户能够在一定程度上了解和参与具体的分析过程。
这方面既可以采用人机交互技术,利用交互式的数据分析过程来引导用户逐步地进行分析,使得用户在得到结果的同时更好地理解分析结果的过程,也可以采用数据溯源技术追溯整个数据分析的过程,帮助用户理解结果。
联系信息:邮箱aoxolcom@163.com或见网站底部。














请登录后发表评论
注册
社交帐号登录