Hadoop共26篇
排序
Spark MLlib简介
MLlib 是 Spark 的机器学习库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。 MLlib 由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优...
Spark DStream相关操作
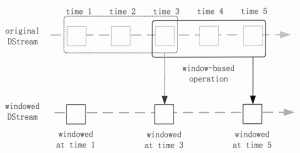
与 RDD 类似,DStream 也提供了自己的一系列操作方法,这些操作可以分成 3 类:普通的转换操作、窗口转换操作和输出操作。 普通的转换操作 普通的转换操作如表 1 所示 表 1 普通的转换操作 Suo ...
Spark开发实例(编程实践)
本节将介绍如何实际动手进行 RDD 的转换与操作,以及如何编写、编译、打包和运行 Spark 应用程序。 启动 Spark Shell Spark 的交互式脚本是一种学习 API 的简单途径,也是分析数据集交互的有力...
Spark总体架构和运行流程
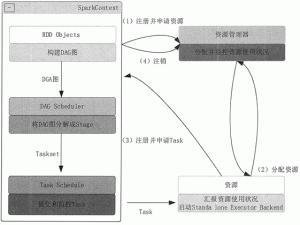
本节将首先介绍 Spark 的运行架构和基本术语,然后介绍 Spark 运行的基本流程,最后介绍 RDD 的核心理念和运行原理。 Spark 总体架构 Spark 运行架构如图 1 所示,包括集群资源管理器(Cluster ...
Spark是什么?Spark和Hadoop的区别
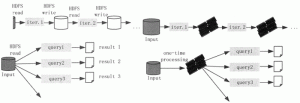
Spark 是加州大学伯克利分校 AMP(Algorithms,Machines,People)实验室开发的通用内存并行计算框架。 Spark 在 2013 年 6 月进入 Apache 成为孵化项目,8 个月后成为 Apache 顶级项目。 Spark...
MapReduce编程实例:单词计数
本节介绍如何编写基本的 MapReduce 程序实现数据分析。本节代码是基于 Hadoop 2.7.3 开发的。 任务准备 单词计数(WordCount)的任务是对一组输入文档中的单词进行分别计数。假设文件的量比较大...
MapReduce执行流程和Shuffle过程
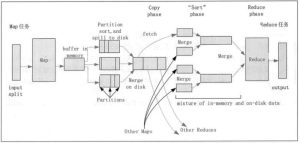
本节将对 Hadoop MapReduce 的工作机制进行介绍,主要从 MapReduce 的作业执行流程和 Shuffle 过程方面进行阐述。通过加深对 MapReduce 工作机制的了解,可以使程序开发者更合理地使用 MapReduc...
Hadoop MapReduce架构
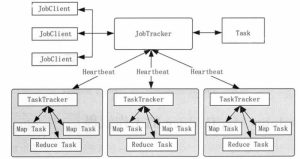
Hadoop MapReduce 是 Hadoop 平台根据 MapReduce 原理实现的计算框架,目前已经实现了两个版本,MapReduce 1.0 和基于 YARN 结构的 MapReduce 2.0。 尽管 MapReduce 1.0 中存在一些问题,但是整...
Hadoop MapReduce简介

本节首先简单介绍大数据批处理概念,然后介绍典型的批处理模式 MapReduce,最后对 Map 函数和 Reduce 函数进行描述。 批处理模式 批处理模式是一种最早进行大规模数据处理的模式。批处理主要操...
ubuntu docker搭建Hadoop集群环境的方法
下面是在Ubuntu上使用Docker搭建Hadoop集群环境的详细方法: 安装Docker和Docker Compose 在Ubuntu上安装Docker和Docker Compose。可以执行以下命令来完成安装: #安装Docker sudo apt-get upda...