HDFS共24篇 第2页
排序
Spark RDD是什么?
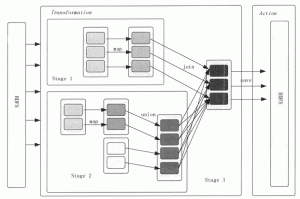
Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。本节...
Spark生态圈简介
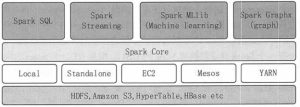
Spark 生态圈是加州大学伯克利分校的 AMP 实验室打造的,是一个力图在算法(Algorithms)、机器(Machines)、人(People)之间通过大规模集成来展现大数据应用的平台。 AMP 实验室运用大数据、...
HBase主要运行机制(物理存储和逻辑架构)
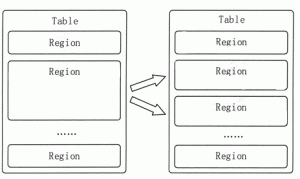
本节将对 HBase 的主要运行机制进行简单介绍。 HBase 的物理存储 HBase 表中的所有行都是按照行键的字典序排列的。因为一张表中包含的行的数量非常多,有时候会高达几亿行,所以需要分布存储到...
ubuntu docker搭建Hadoop集群环境的方法
下面是在Ubuntu上使用Docker搭建Hadoop集群环境的详细方法: 安装Docker和Docker Compose 在Ubuntu上安装Docker和Docker Compose。可以执行以下命令来完成安装: #安装Docker sudo apt-get upda...
Spark Streaming编程模型,DStream 的操作流程和使用方法
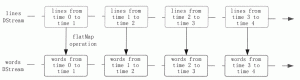
本节将介绍 Spark Streaming 的编程模型,包括 DStream 的操作流程和使用方法。 DStream 的操作流程 DStream 作为 Spark Streaming 的基础抽象,它代表持续性的数据流。这些数据流既可以通过外...
MapReduce执行流程和Shuffle过程
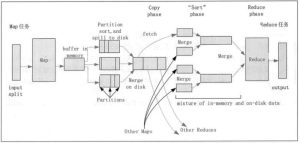
本节将对 Hadoop MapReduce 的工作机制进行介绍,主要从 MapReduce 的作业执行流程和 Shuffle 过程方面进行阐述。通过加深对 MapReduce 工作机制的了解,可以使程序开发者更合理地使用 MapReduc...
Hadoop MapReduce简介

本节首先简单介绍大数据批处理概念,然后介绍典型的批处理模式 MapReduce,最后对 Map 函数和 Reduce 函数进行描述。 批处理模式 批处理模式是一种最早进行大规模数据处理的模式。批处理主要操...