HDFS共24篇 第2页
排序
ubuntu docker搭建Hadoop集群环境的方法
下面是在Ubuntu上使用Docker搭建Hadoop集群环境的详细方法: 安装Docker和Docker Compose 在Ubuntu上安装Docker和Docker Compose。可以执行以下命令来完成安装: #安装Docker sudo apt-get upda...
HBase Java API编程实例

本节通过一个具体的编程实例来学习如何使用 HBase Java API 解决实际问题。在本实例中,首先创建一个学生成绩表 scores,用来存储学生各门课程的考试成绩,然后向 scores 添加数据。 表 scores ...
MapReduce编程实例:单词计数
本节介绍如何编写基本的 MapReduce 程序实现数据分析。本节代码是基于 Hadoop 2.7.3 开发的。 任务准备 单词计数(WordCount)的任务是对一组输入文档中的单词进行分别计数。假设文件的量比较大...
HDFS架构和实现机制简介 HDFS 是什么?
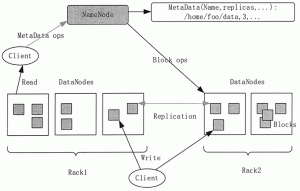
HDFS 整体架构 HDFS 是一个主从 Master/Slave 架构。一个 HDFS 集群包含一个 NameNode,这是一个 Master Server,用来管理文件系统的命名空间,以及调节客户端对文件的访问。一个 HDFS 集群还包...
Spark Streaming的系统架构
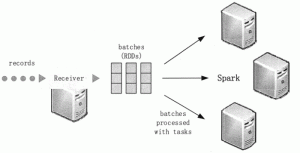
本节首先分析传统流处理系统架构存在的问题,然后介绍 Spark Streaming 的系统架构及其工作原理和优势。 传统流处理系统架构 流处理架构的分布式流处理管道执行方式是,首先用数据采集系统接收...
Hadoop MapReduce简介

本节首先简单介绍大数据批处理概念,然后介绍典型的批处理模式 MapReduce,最后对 Map 函数和 Reduce 函数进行描述。 批处理模式 批处理模式是一种最早进行大规模数据处理的模式。批处理主要操...
MapReduce实例分析:单词计数
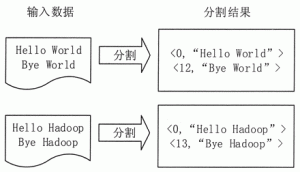
单词计数是最简单也是最能体现 MapReduce 思想的程序之一,可以称为 MapReduce 版“Hello World”。单词计数的主要功能是统计一系列文本文件中每个单词出现的次数。本节通过单词计数实例来阐述...
MapReduce执行流程和Shuffle过程
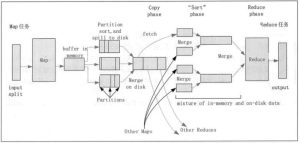
本节将对 Hadoop MapReduce 的工作机制进行介绍,主要从 MapReduce 的作业执行流程和 Shuffle 过程方面进行阐述。通过加深对 MapReduce 工作机制的了解,可以使程序开发者更合理地使用 MapReduc...
Spark生态圈简介
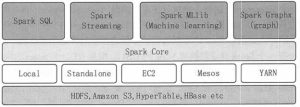
Spark 生态圈是加州大学伯克利分校的 AMP 实验室打造的,是一个力图在算法(Algorithms)、机器(Machines)、人(People)之间通过大规模集成来展现大数据应用的平台。 AMP 实验室运用大数据、...
Spark Streaming编程模型,DStream 的操作流程和使用方法
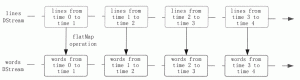
本节将介绍 Spark Streaming 的编程模型,包括 DStream 的操作流程和使用方法。 DStream 的操作流程 DStream 作为 Spark Streaming 的基础抽象,它代表持续性的数据流。这些数据流既可以通过外...