
服务器共1120篇 第91页
服务器英文名称为“Server”,指的是在网络环境中为客户机(client)提供各种服务的、特殊的专用计算机。在网络中,服务器承担着数据的存储、转发、发布等关键任务,是各类基于客户机/服务器 (C/S) 模式或 B/S 模式网络中不可或缺的重要组成部分。
排序
oracle初始化参数的设置方法
oracle初始化参数设置。 ALTER DATABASE DATAFILE'd:ORANTDATABASEUSER1ORCL.ORA' RESIZE 1000M; CREATE TABLESPACE INDEX_DATA DATAFILE'd:ORANTDATABASEINDEX_DATA' SIZE 500M; ALTER DATABAS...
在Linux下安装Oracle的方法
在Linux下安装Oracle。由于Oracle自身比较复杂,在Linux环境下安装要涉及很多方面的因素。本文分两个方面介绍在Linux RedHat 6.0环境下Oracle 8.0.5的安装。 一、调整Linux核心与环境 在安装Ora...
常见数据库系统与Oracle数据库比较
提起数据库,第一个想到的公司,一般都会是Oracle。该公司成立于1977年,最初是一家专门开发数据库的公司。Oracle在数据库领域一直处于领先地位。1984年,首先将关系数据库转到了桌面计算机上。...
Spark DStream相关操作
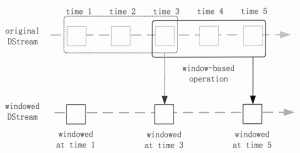
与 RDD 类似,DStream 也提供了自己的一系列操作方法,这些操作可以分成 3 类:普通的转换操作、窗口转换操作和输出操作。 普通的转换操作 普通的转换操作如表 1 所示 表 1 普通的转换操作 Suo ...
Spark是什么?Spark和Hadoop的区别
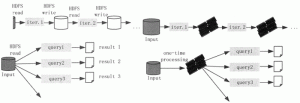
Spark 是加州大学伯克利分校 AMP(Algorithms,Machines,People)实验室开发的通用内存并行计算框架。 Spark 在 2013 年 6 月进入 Apache 成为孵化项目,8 个月后成为 Apache 顶级项目。 Spark...
MapReduce执行流程和Shuffle过程
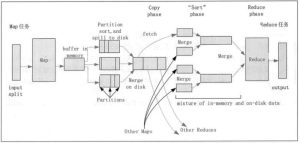
本节将对 Hadoop MapReduce 的工作机制进行介绍,主要从 MapReduce 的作业执行流程和 Shuffle 过程方面进行阐述。通过加深对 MapReduce 工作机制的了解,可以使程序开发者更合理地使用 MapReduc...
Hadoop MapReduce简介

本节首先简单介绍大数据批处理概念,然后介绍典型的批处理模式 MapReduce,最后对 Map 函数和 Reduce 函数进行描述。 批处理模式 批处理模式是一种最早进行大规模数据处理的模式。批处理主要操...
HBase主要运行机制(物理存储和逻辑架构)
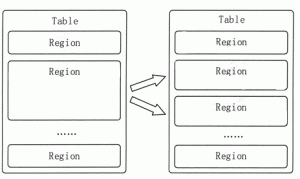
本节将对 HBase 的主要运行机制进行简单介绍。 HBase 的物理存储 HBase 表中的所有行都是按照行键的字典序排列的。因为一张表中包含的行的数量非常多,有时候会高达几亿行,所以需要分布存储到...
HBase Shell常用命令和基本操作(附带实例)

HBase 为用户提供了一个非常方便的命令行使用方式——HBase Shell。 HBase Shell 提供了大多数的 HBase 命令,通过 HBase Shell,用户可以方便地创建、删除及修改表,还可以向表中添加数据,列...
NoSQL非关系型数据库简介及与关系数据库的区别
虽然关系型数据库系统很优秀,但是在大数据时代,面对快速增长的数据规模和日渐复杂的数据模型,关系型数据库系统已无法应对很多数据库处理任务。 NoSQL 凭借易扩展、大数据量和高性能及灵活的...









